
اینروزها همهجا صحبت از هوش مصنوعی یا AI است. مشکلات «حلنشدنی» در حال حل شدن هستند؛ افرادی که هیچ دانشی از کدنویسی یا آهنگسازی یا طراحی ندارند، به کمک AI و در عرض چند ثانیه وبسایت و آهنگ میسازنند و طرحهای هنری شگفتانگیز خلق میکنند. شرکتهای بزرگ نیز درحال سرمایهگذاریهای چند میلیارد دلاری در پروژههای هوش مصنوعی هستند و مایکروسافت هم با آوردن چتبات ChatGPT به بینگ، در تلاش است مدل جستجوی ما در اینترنت را زیرورو کند و شاید حتی تا چند وقت دیگر، ساختار کل اینترنت را به هم بریزد.
سر در آوردن از هوش مصنوعی هم مثل هر تکنولوژی جدید دیگر که با کلی هیاهو و جنجال رسانهای همراه است، ممکن است گیجکننده باشد و حتی متخصصان هوش مصنوعی هم بهسختی میتوانند خود را با تحولات لحظهای این فناوری همراه کنند.
در زمینهی هوش مصنوعی، یک سری سوالات به مراتب پرسیده میشود؛ مثلا اینکه دقیقا منظور از هوش مصنوعی چیست؟ فرق بین هوش مصنوعی، یادگیری ماشین و یادگیری عمیق چیست؟ چه مسائل دشواری حالا بهراحتی قابل حل هستند و حل چه مسائلی هنوز از توانایی هوش مصنوعی خارج است؟ و شاید محبوبترین آنها؛ آیا قرار است دنیا با هوش مصنوعی نابود شود؟
اگر برای شما نیز سوال شده که این همه هیاهو و هیجان بر سر هوش مصنوعی بهخاطر چیست و اگر دوست دارید پاسخ این پرسشها را به زبانی ساده یاد بگیرید، با ما همراه شوید تا نگاهی به پشت پردهی این فناوری مرموز و قدرتمند بیندازیم.
فهرست مطالب
- هوش مصنوعی چیست؟
- تاریخچه هوش مصنوعی
- انواع هوش مصنوعی
- یادگیری ماشین (Machine Learning)
- یادگیری عمیق (Deep Learning)
- کاربرد هوش مصنوعی
- تشخیص اجسام (Object Recognition)
- تشخیص چهره (Face Recognition)
- تشخیص گفتار (Speech Recognition)
- دیپفیک و شبکههای مولد (Deepfakes and Generative AI)
- نمونههای هوش مصنوعی
- ChatGPT
- DALL-E
- Copilot
- Jukebox
- Midjourney
- New Bing
- LaMDA
- PaLM
- خطرات هوش مصنوعی
- آینده هوش مصنوعی
- آیا هوش مصنوعی بشر را نابود میکند؟
هوش مصنوعی چیست؟
اصطلاح «هوش مصنوعی» (Artificial Intelligence) یا AI برای توصیف سیستمی بهکار میرود که میتواند فعالیتهای شناختی وابسته به ذهن انسان ازجمله «یادگیری» و «حل مسئله» را بهخوبی یا حتی بهتر از انسانها انجام دهد. اما در اکثر موارد، آنچه بهعنوان هوش مصنوعی میشناسیم، درواقع «اتوماسیون» (Automation) یا همان فرایند خودکارسازی نام دارد و برای درک بهتر AI، ابتدا باید فرق آن را با اتوماسیون بدانیم.
در دنیای علوم کامپیوتر یک جوک قدیمی وجود دارد که میگوید اتوماسیون، کارهایی است که ما همینحالا میتوانیم با کامپیوتر انجام دهیم، اما هوش مصنوعی کارهایی است که ما دلمان میخواست میتوانستیم با کامپیوتر انجام دهیم. بهعبارت دیگر، بهمحض اینکه بفهمیم چطور کاری را با کامپیوتر انجام دهیم، از حوزهی هوش مصنوعی خارج و وارد اتوماسیون میشویم.
دلیل وجود این جوک این است که هوش مصنوعی تعریف دقیقی ندارد و حتی اصطلاح فنی نیست. اگر به ویکیپدیا نگاهی بیندازید، میخوانید که هوش مصنوعی «هوشی است که توسط ماشینها ظهور پیدا میکند، در مقابل هوش طبیعی که توسط جانوران شامل انسانها نمایش مییابد.» یعنی تعریفی به همین مبهمی و گستردگی.
بهطور کلی، دو نوع هوش مصنوعی وجود دارد: هوش مصنوعی قوی (strong AI) و هوش مصنوعی ضعیف (weak AI).
هوش مصنوعی قوی همانی است که اکثر افراد با شنیدن AI متصور میشوند؛ یعنی نوعی هوش دانای کل شبیه شخصیت هال ۹۰۰۰، همان ربات قاتلِ فیلم ادیسهی فضایی یا سیستم خودآگاه هوش مصنوعی اسکاینت در فیلمهای تریمیناتور که در عین داشتن هوش فراانسانی و قابلیت استدلال و تفکر منطقی، تواناییهایی فراتر از انسانها نیز دارند.
آنچه از هوش مصنوعی تابهحال دیدهایم از نوع هوش مصنوعی ضعیف است
درمقابل، هوش مصنوعی ضعیف الگوریتمهای بسیار تخصصیای هستند که برای پاسخ به سوالات مشخص، مفید و محدود به حیطهی همان مسئله طراحی شدهاند؛ مثل موتور جستجوی گوگل و بینگ، الگوریتم پیشنهاد فیلم نتفلیکس یا حتی دستیار صوتی Siri و گوگلاسیستنت. این مدل AIها در سطح خود بسیار قابلتوجه هستند، هرچند کارایی آنها محدود است.
اما فیلمهای علمیتخیلی هالیوودی را که کنار بگذاریم، هنوز با دستیابی به هوش مصنوعی قوی فاصلهی زیادی داریم. درحالحاضر، تمام AIهایی که میشناسیم از نوع ضعیف هستند و برخی از پژوهشگران معتقدند روشهایی که تابهحال برای توسعهی هوش مصنوعی ضعیف به کار رفتهاند، کاربردی در توسعهی هوش مصنوعی قوی نخواهند داشت. البته اگر نظر کارمندان شرکت OpenAI، توسعهدهندهی چتبات محبوب ChatGPT را بپرسید، به شما خواهند گفت تا ۱۳ سال آینده و با همین روشهای شناختهشده میتوانند به هوش مصنوعی قوی دست پیدا کنند!

اگر بخواهیم در این موضوع خیلی دقیق شویم، باید بگوییم که «هوش مصنوعی» درحالحاضر بیشتر اصطلاحی برای جلبتوجه و بازاریابی است تا اصطلاحی فنی. دلیل اینکه شرکتها به جای استفاده از واژهی «اتوماسیون» از هوش مصنوعی استفاده میکنند این است که میخواهند در ذهن ما همان تصاویر علمیتخیلی فیلمهای هالیوودی را تداعی کنند. اما این کار کاملا هم زرنگبازی و فریبکاری نیست؛ اگر بخواهیم دستودلبازی به خرج دهیم، میتوان گفت این شرکتها قصد دارند بگویند درست است که تا رسیدن به هوش مصنوعی قوی راه درازی در پیش داریم، اما AI ضعیف کنونی را هم نباید دستکم گرفت، چون بهمراتب از چند سال پیش، قویتر شده است که خب، این حرف کاملاً درست است.
در برخی زمینهها، تغییرات شگرفی در توانایی ماشینها صورت گرفته و آن هم بهخاطر پیشرفتهایی است که در چند سال اخیر، در دو زمینهی مرتبط با هوش مصنوعی، یعنی یادگیری ماشین (Machine Learning) و یادگیری عمیق (Deep Learning) بهدست آمده است. این دو اصطلاح را هم احتمالا بسیار شنیدهاید و در ادامه دربارهی سازوکارشان توضیح خواهیم داد. اما پیش از آن، اجازه دهید کمی دربارهی تاریخچهی جالب و خواندنی هوش مصنوعی با شما صحبت کنیم.
تاریخچه هوش مصنوعی
آیا ماشینها میتوانند فکر کنند؟
در نیمهی اول قرن بیستم، داستانهای علمیتخیلی، مردم را با مفهوم رباتهای هوشمند آشنا کردند که اولین آنها، شخصیت مرد حلبی در رمان «جادوگر شهر اُز» (۱۹۰۰) بود. تا اینکه در دههی ۱۹۵۰، نسلی از دانشمندان، ریاضیدانان و فیلسوفانی را داشتیم که ذهنشان با مفهوم هوش مصنوعی درگیر شد. یکی از این افراد، ریاضیدان و دانشمند کامپیوتر انگلیسی بهنام آلن تورینگ (Alan Turing) بود که سعی داشت امکان دستیابی به هوش مصنوعی را با علم ریاضی بررسی کند.
تورینگ میگفت انسانها از اطلاعات موجود و همچنین قدرت استدلال برای تصمیمگیری و حل مشکلات استفاده میکنند، پس چرا ماشینها نمیتوانند همین کار را انجام دهند؟ این دغدغهی ذهنی درنهایت به نوشتن مقالهی بسیار معروفی در سال ۱۹۵۰ انجامید که با پرسش جنجالی «آیا ماشینها میتوانند فکر کنند؟» شروع میشد. تورینگ در این مقاله به شرح چگونگی ساخت ماشینهای هوشمند و آزمایش سطح هوشمندی آنها پرداخت و با پرسش «آیا ماشینها میتوانند از بازی تقلید سربلند بیرون آیند؟»، آغازگر آزمون بسیار معروف «تست تورینگ» شد.
نبود حافظه و هزینههای سرسامآور کامپیوترها، تورینگ را از تست نظریهاش بازداشت
اما مقالهی تورینگ تا چند سال در حد نظریه باقی ماند، چراکه آن زمان کامپیوترها از پیشنیاز کلیدی برای هوشمندی، بیبهره بودند؛ اینکه نمیتوانستند دستورات را ذخیره کنند و فقط میتوانستند آنها را اجرا کنند. بهعبارت دیگر، میشد به کامپیوترها گفت چه کنند، اما نمیشد از آنها خواست کاری را که انجام دادهاند، بهخاطر بیاورند.
مشکل بزرگ دوم، هزینههای سرسامآور کار با کامپیوتر بود. اوایل دههی ۱۹۵۰، هزینهی اجارهی کامپیوتر تا ۲۰۰ هزار دلار در ماه میرسید؛ بههمینخاطر، فقط دانشگاههای معتبر و شرکتهای بزرگ فناوری میتوانستند به این حوزه وارد شوند. اگر آنروزها کسی میخواست برای پژوهشهای هوش مصنوعی، فاند دریافت کند، لازم بود که ابتدا ممکن بودن ایدهی خود را اثبات میکرد و بعد، از حمایت و تأیید افراد بانفوذ بهرهمند میشد.
کنفرانس تاریخی DSRPAI که همهچیز با آن شروع شد
پنج سال بعد، سه پژوهشگر علوم کامپیوتر بهنامهای الن نیوول، کلیف شا و هربرت سایمون نرمافزار Logic Theorist را توسعه دادند که توانست ممکن بودن ایدهی هوش ماشینی تورینگ را اثبات کند. این برنامه که با بودجهی شرکت تحقیق و توسعهی RAND توسعه داده شده بود، بهگونهای طراحی شده بود تا مهارتهای حل مسئلهی انسان را تقلید کند.
اصطلاح «هوش مصنوعی» توسط جان مککارتی در سال ۱۹۵۶ ابداع شد
بسیاری، Logic Theorist را اولین برنامهی هوش مصنوعی میدانند. این برنامه در پروژهی تحقیقاتی تابستانی کالج دارتموث در زمینهی هوش مصنوعی (DSRPAI) به میزبانی جان مککارتی (John McCarthy) و ماروین مینسکی (Marvin Minsky) در سال ۱۹۵۶ ارائه شد.

در این کنفرانس تاریخی، مککارتی پژوهشگران برتر در حوزههای مختلف را برای بحث آزاد در مورد هوش مصنوعی(اصطلاحی که خود مککارتی در همان رویداد ابداع کرد)، دور هم جمع کرد، با این تصور که با همکاری جمعی دستیابی به هوش مصنوعی ممکن میشد. اما کنفرانس نتوانست انتظارات مککارتی را برآورده کند، چراکه هیچ هماهنگی بین پژوهشگران نبود؛ آنها به دلخواه خود میآمدند و میرفتند و در مورد روشهای استاندارد برای انجام پژوهشهای هوش مصنوعی به هیچ توافقی نرسیدند. بااینحال، تمام شرکتکنندگان از صمیم قلب این حس را داشتند که هوش مصنوعی قابل دستیابی است.
اهمیت کنفرانس DSRPAI غیرقابلوصف است؛ چراکه ۲۰ سال پژوهش حوزهی هوش مصنوعی برمبنای آن صورت گرفت.
ترن هوایی موفقیتها و شکستهای هوش مصنوعی
از سالهای ۱۹۵۷ تا ۱۹۷۴، بهعنوان دوران شکوفایی هوش مصنوعی یاد میشود. در این دوره، کامپیوترها سریعتر، ارزانتر و فراگیرتر شدند و میتوانستند اطلاعات بیشتری را ذخیره کنند. الگوریتمهای یادگیری ماشین نیز بهبود یافتند و افراد، بهتر میدانستند کدام الگوریتم را برای حل کدام مشکل به کار برند.
نمونه برنامههای کامپیوتری اولیه مانند General Problem Solver نیوول و سایمون یا نرمافزار ELIZA که سال ۱۹۶۶ توسط جوزف وایزنبام طراحی شده و اولین چتباتی بود که توانست آزمون تورینگ را با موفقیت پشت سر بگذارد، بهترتیب، دانشمندان را چند قدم به اهداف «حل مسئله» و «تفسیر زبان گفتاری» نزدیکتر کرد.
در این زمان پژوهشگران به آینده هوش مصنوعی بسیار خوشبین بودند
این موفقیتها همراهبا حمایت پژوهشگران برجستهای که در کنفرانس DSRPAI شرکت کرده بودند، سرانجام سازمانهای دولتی مانند آژانس پروژههای تحقیقاتی پیشرفته دفاعی آمریکا (دارپا) را متقاعد کرد تا بودجهی لازم برای پژوهشهای هوش مصنوعی را در چندین موسسه تأمین کنند. دولت آمریکا بهویژه به توسعهی ماشینی علاقهمند بود که بتواند هم زبان گفتاری و هم پردازش دادهها را با توان عملیاتی بالا رونویسی و ترجمه کند.
در این زمان، پژوهشگران به آیندهی این حوزه بسیار خوشبین بودند و سطح توقعاتشان حتی از میزان خوشبینیشان هم بالاتر بود؛ بهطوری که در سال ۱۹۷۰، ماروین مینسکی به مجله لایف گفت: «سه تا هشت سال آینده، ما به ماشینی با هوش عمومی یک انسان عادی دست خواهیم یافت.» با این حال، اگرچه امکان رسیدن به هوش مصنوعی برای همه اثبات شده بود، هنوز راه بسیار درازی تا دستیابی به اهداف نهایی پردازش زبان طبیعی، تفکر انتزاعی و خویشتنآگاهی در ماشینها باقی مانده بود.
موانع زیادی سر راه تحقق این اهداف قرار داشت که بزرگترینشان، نبود قدرت رایانشی کافی برای انجام پروژهها بود. کامپیوترهای آن زمان نه جای کافی برای ذخیرهی حجم عظیمی از اطلاعات داشتند و نه سرعت لازم برای پردازش آنها. هانس موراوک، دانشجوی دکترای مککارتی در آن زمان، گفت که «کامپیوترها آن موقع میلیونها بار ضعیفتر از آن بودند که بتوانند هوشی از خود نشان دهند». وقتی کاسهی صبر پژوهشگران لبریز شد، بودجههای دولتی نیز کاهش یافت و تا ده سال، سرعت پژوهشهای هوش مصنوعی بهشدت کند شد.
تا اینکه در دههی ۱۹۸۰، دو عامل جان دوبارهای به پژوهشهای هوش مصنوعی بخشیدند؛ بهبود چشمگیر در الگوریتمها و از راه رسیدن بودجههای جدید.
بهبود چشمگیر در الگوریتمها جان دوبارهای به پژوهشهای هوش مصنوعی بخشید
جان هاپفیلد (John Hopfield) و دیوید روملهارت (David Rumelhart) تکنیکهای «یادگیری عمیق» (Deep Learning) را گسترش دادند که به کامپیوترها اجازه میداد خودشان با تجربه کردن، چیزهای جدید یاد بگیرند. از آن طرف هم، دانشمند آمریکایی علوم کامپیوتر، ادوارد فاینباوم (Edward Feigenbaum)، «سیستمهای خبره» (Expert Systems) را معرفی کرد که فرایند تصمیمگیری افراد متخصص را تقلید میکردند. این سیستم از افراد خبره در زمینههای مختلف میپرسید که در موقعیتی خاص، چه واکنشی نشان میدهند و بعد پاسخهای آنها را در اختیار افراد غیرمتخصص قرار میداد تا آنها از برنامه یاد بگیرند.
از سیستمهای خبره بهطور گسترده در صنایع استفاده شد. دولت ژاپن بهعنوان بخشی از پروژهی نسل پنجم کامپیوتر (FGCP)، سرمایهگذاری کلانی در سیستمهای خبره و دیگر پروژههای هوش مصنوعی انجام داد. از سال ۱۹۸۲ تا ۱۹۹۰، ژاپن ۴۰۰ میلیون دلار برای ایجاد تحول در پردازشهای کامپیوتری، اجرای برنامهنویسی منطقی و بهبود هوش مصنوعی هزینه کرد.
متاسفانه، اکثر این اهداف بلندپروازانه محقق نشد؛ اما میتوان این طور به قضیه نگاه کرد که پروژهی FGCP ژاپن بهطور غیرمستقیم الهامبخش نسلی از مهندسان و دانشمندان جوان شد تا به دنیای هوش مصنوعی قدم بگذارند. درنهایت، بودجهی FGCP هم روزی به سر رسید و هوش مصنوعی بار دیگر از کانون توجه خارج شد.
شکست قهرمان شطرنج دنیا دربرابر دیپبلو؛ اولین گام بزرگ به سمت توسعه AI با قابلیت تصمیمگیری
از قضا، هوش مصنوعی در نبود بودجهی دولتی و هیاهوی تبلیغاتی، فرصت دیگری برای رشد پیدا کرد. در طول دهههای ۱۹۹۰ و ۲۰۰۰، بسیاری از اهداف مهم هوش مصنوعی محقق شد. در سال ۱۹۹۷، ابرکامپیوتر شطرنجبازی به نام دیپ بلو (Deep Blue) ساخته شرکت IBM توانست گری کاسپارف، استاد بزرگ و قهرمان شطرنج جهان را شکست دهد. در این مسابقه که با هیاهوی رسانهای بزرگی همراه بود، برای نخستین بار در تاریخ، قهرمان شطرنج جهان در برابر کامپیوتر شکست خورد و از آن بهعنوان اولین گام بزرگ بهسوی توسعهی برنامهی هوش مصنوعی با قابلیت تصمیمگیری یاد میشود.
در همان سال، نرمافزار تشخیص گفتار شرکت Dragon System روی ویندوز پیادهسازی شد. این هم گام بزرگ دیگری در حوزهی هوش مصنوعی، اما در جهت اهداف تفسیر زبان گفتاری بود. اینطور به نظر میرسید که دیگر مسئلهای وجود ندارد که ماشینها نتوانند از پس آن برآیند. حتی پای احساسات انسانی هم به ماشینها باز شد؛ ربات کیزمت (Kismet) که در دههی ۱۹۹۰ توسط سینتیا بریزیل (Cynthia Breazeal) در دانشگاه MIT ساخته شد، میتوانست احساسات را درک و حتی آنها را به نمایش بگذارد.
زمان؛ مرهم تمام زخمها
دانشمندان هنوز از همان روشهای چند دههی پیش برای برنامهنویسی هوش مصنوعی استفاده می کنند؛ اما چه شد که حالا به دستاوردهای چشمگیری مثل چتبات ChatGPT و مولد تصویر Dall-E و Midjourney رسیدیم؟
پاسخ این است که مهندسان سرانجام موفق شدند مشکل محدودیت ذخیرهسازی کامپیوترها را حل کنند. قانون مور (Moore’s Law) که تخمین میزند حافظه و سرعت کامپیوترها هر سال دوبرابر میشود، بالاخره توانست به وقوع بپیوندد و حتی در بسیاری از موارد، از این حد هم فراتر برود. درواقع، دلیل شکست گری کاسپارف در سال ۱۹۹۷ و شکست قهرمان بازی تختهای گو، که جی (Ke Jie) در سال ۲۰۱۷ دربرابر برنامهی AlphaGo گوگل به همین افزایش سرعت و حافظهی کامپیوترها برمیگردد. این قضیه، روند پژوهشهای هوش مصنوعی را کمی توضیح میدهد؛ اینکه ما قابلیتهای هوش مصنوعی را تا سطح قدرت محاسباتی فعلی (از نظر سرعت پردازش و حافظهی ذخیریسازی) توسعه میدهیم و بعد منتظر میمانیم تا قانون مور دوباره به ما برسد.
دلیل شکست انسانها از هوش مصنوعی؛ افزایش سرعت و حافظه کامپیوترها
ما اکنون در عصر «کلانداده» زندگی میکنیم؛ عصری که در آن توانایی جمعآوری حجم عظیمی از اطلاعات را داریم که پردازش تمام آنها توسط انسانها بینهایت دشوار و وقتگیر است. استفاده از هوش مصنوعی در صنایع مختلفی ازجمله تکنولوژی، بانکداری، مارکتینگ و سرگرمی، این دشواری را تاحدود زیادی حل کرده است. مدلهای زبانی بزرگ که در چتبات ChatGPT به کار رفتهاند، به ما نشان دادند که حتی اگر الگوریتمها پیشرفت چندانی نداشته باشند، کلانداده و محاسبات عظیم میتوانند به هوش مصنوعی کمک کنند که خودش یاد بگیرد و عملکردش را بهتر کند.
شاید شواهدی وجود داشته باشد که نشان میدهد سرعت قانون مور، بهویژه در دنیای تراشهها، کند شده است، اما افزایش حجم اطلاعات با سرعت سرسامآوری در حال پیشروی است. پیشرفتهایی که در علوم کامپیوتر، ریاضیات یا علوم اعصاب به دست میآیند همگی میتوانند بشر را از تنگای محدودیت قانون مور عبور دهند. و این یعنی، پیشرفت بشر در تکنولوژی هوش مصنوعی به این زودیها به پایان نخواهد رسید.
انواع هوش مصنوعی
هوش مصنوعی به روشهای مختلفی دستهبندی میشود؛ جدا از دستهبندی بسیار کلی هوش مصنوعی ضعیف و هوش مصنوعی قوی که در ابتدای مقاله دربارهاش صحبت کردیم، روش رایج دیگری هوش مصنوعی را به چهار دسته تقسیم میکند:
۱) ماشینهای واکنشی (Reactive Machines) که سادهترین نوع هوش مصنوعی هستند و تنها میتوانند به موقعیتهای فعلی بدون استفاده از تجربیات گذشته پاسخ دهند؛ مثل موتورجستجوی گوگل.
۲) ماشینهای حافظه محدود (Limited Memory) که میتوانند از برخی دادههای گذشته برای بهبود تصمیمگیری استفاده کنند؛ مثل سیستم احراز هویت در وبسایتها.
۳) نظریه ذهن (Theory of Mind) که درحالحاضر نوع فرضی هوش مصنوعی است که میتواند به شکل بهتری احساسات، عواطف و اعتقادات انسانها را درک و سپس از این اطلاعات برای تصمیمگیری خود استفاده کند.
۴) هوش مصنوعی خودآگاه (Self-aware) که آن هم یکی دیگر از انواع فرضی هوش مصنوعی است که به خودآگاهی رسیده و میتواند از خودش احساسات و افکار شبیه انسانها داشته باشد.
اما کاربردیترین دستهبندی هوش مصنوعی که کاری به فرضیهها و نظریات ندارد و صرفا آنچه تاکنون به دست آمده را تشریح میکند، «یادگیری ماشین» (Machine learning) و «یادگیری عمیق» (Deep learning) است که نوعی از آنها تقریبا در تمام سیستمهای هوش مصنوعی امروزی به کار رفته است.
اگر مدتها برایتان سوال بوده که این دو اصطلاح دقیقا به چه معنی هستند، اما هنوز جواب این سوال را بهطور دقیق نمیدانید، نگران نباشید؛ ما اینجا تلاش خواهیم کرد به سادهترین شکل ممکن، این دو مبحث بسیار پیچیده را توضیح دهیم.
یادگیری ماشین (Machine Learning)
یادگیری ماشین روش خاصی برای ایجاد هوش مصنوعی است. فرض کنید میخواهیم موشکی را پرتاب و محل فرود آن را پیشبینی کنیم. این کار البته آنقدرها سخت نیست؛ گرانش مبحث جاافتادهای است و میتوان معادلات مربوط را نوشت و حساب کرد براساس چند متغیر از جمله سرعت و موقعیت، موشک فرضی کجا فرود خواهد آمد.
اما وقتی پای متغیرهای ناشناخته وسط میآید، دیگر نمیتوان به این راحتی جواب سوال را پیدا کرد. این بار فرض کنید میخواهیم کامپیوتر به تعدادی تصویر نگاه کند و بگوید آیا در بین آنها تصویری از گربه بوده است یا خیر. برای این سوال چه نوع معادلهای میتوانیم بنویسیم که تمام ترکیبهای ممکن سبیل و گوش گربه از زوایای مختلف را برای کامپیوتر توصیف کند؟
اینجا است که یادگیری ماشین به کمک دانشمندان میآید؛ به جای اینکه خودمان فرمول و قوانین را بنویسیم، سیستمی میسازیم که بتواند قوانین را با مشاهدهی چندین نمونه عکس، برای خودش بنویسد. بهعبارتدیگر، به جای اینکه بخواهیم گربه را توصیف کنیم، به هوش مصنوعی تعداد زیادی تصویر گربه نشان دهیم و اجازه میدهیم خودش متوجه شود چه چیزی گربه است و چه چیزی گربه نیست.
یادگیری ماشین برای دنیای کنونی لبریز از دادهی ما فوقالعاده است، چرا که سیستمی که بتواند قوانین خودش را براساس داده یاد بگیرد، میتواند با دادههای بیشتر بهبود یابد. میخواهید سیستمتان در تشخیص گربه ماهرتر شود؟ خب اینترنت در همین لحظه دارد میلیونها تصویر گربه تولید میکند!
یکی از دلایلی که یادگیری ماشین در چند سال اخیر تا این اندازه محبوب شده، همین افزایش چشمگیر حجم داده در اینترنت است؛ دلیل دیگر به نحوهی استفاده از این دادهها مربوط میشود. در بحث یادگیری ماشین، به جز داده، دو سوال مرتبط دیگر نیز مطرح میشود:
۱) چطور چیزی را که یاد گرفتم، به خاطر بسپارم؟ در کامپیوتر چطور قوانین و روابطی را که از نمونه داده استخراج کردهام، ذخیره کنم و نمایش دهم؟
۲) چطور فرایند یادگیری را انجام دهم؟ چطور قوانین و روابطی را که در پاسخ به نمونههای قبلی ذخیره کردهام، برای نمونههای جدید تغییر داده و بهتر شوم؟
بهعبارت دیگر، چیزی که دارد از این همه داده، یاد میگیرد دقیقا چیست؟
در یادگیری ماشین انتخاب نوع مدل بسیار مهم است
در یادگیری ماشین، به نمایش کامپیوتری چیزهای یاد گرفته شده و ذخیره شده، «مدل» میگویند. اینکه از چه مدلی استفاده کنید، بسیار مهم است، چون این مدل است که روش یادگیری هوش مصنوعی، نوع دادههایی که میتواند از آن بیاموزد و نوع سوالهایی را که میتوان از آن پرسید، مشخص میکند.
بیایید این موضوع را با یک مثال ساده روشنتر کنیم. فرض کنید برای خرید انجیر به میوهفروشی رفتهایم و میخواهیم بهکمک یادگیری ماشین بفهمیم کدام انجیرها رسیدهاند. کار آسانی باید باشد، چون میدانیم هرچه انجیر نرمتر باشد، رسیدهتر و شیرینتر خواهد بود. میتوانیم چند نمونه انجیر رسیده و کال را انتخاب کرده، میزان شیرینی آنها را مشخص کنیم و بعد اطلاعاتشان را روی نمودار خطی قرار دهیم. این خط همان «مدل» ما است. اگر دقت کنید، همین خط ساده، ایدهی «هرچه نرمتر باشد، شیرینتر است» را بدون اینکه لازم باشد ما چیزی بنویسیم، نشان میدهد. هوش مصنوعی نوپای ما هنوز چیزی درباره میزان قند یا چگونگی رسیده شدن میوهها نمیداند، اما میتواند میزان شیرینی آنها را با فشار دادن و اندازهگیری نرمی پیشبینی کند.
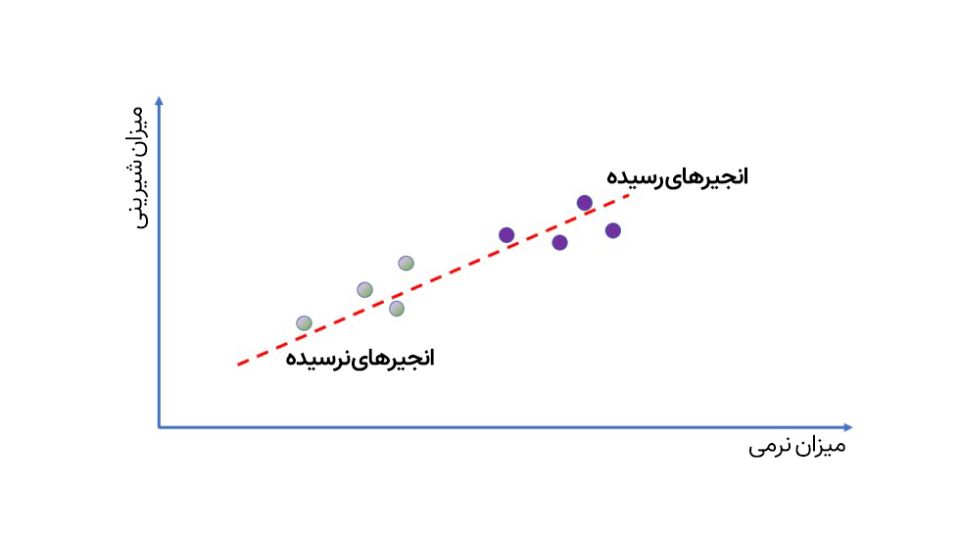

همانطور که در تصویر سمت راست میبینید، هوش مصنوعی سادهی ما بدون اینکه چیزی دربارهی میزان شیرینی بداند یا اینکه میوهها چطور رسیده میشوند، میتواند پیشبینی کند که با فشردن میوه و تشخیص نرمی آن، چقدر شیرین است.
برای بهبود مدل، میتوان نمونههای بیشتری جمعآوری کرد و خط دیگری را برای پیشبینی دقیقتر کشید(مانند تصویر سمت چپ).
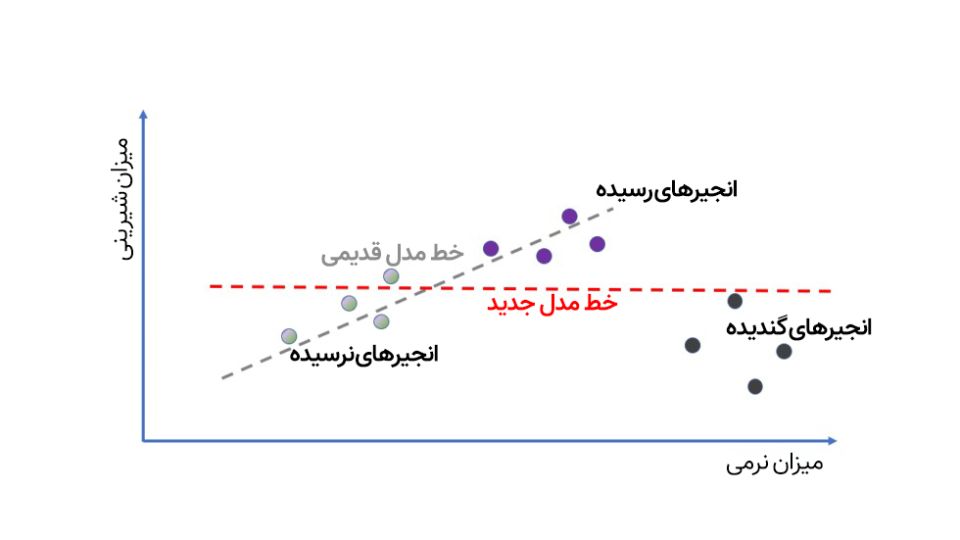
اما مشکلات بلافاصله خودشان را نشان میدهند. ما تا اینجا داشتیم AI انجیرمان را براساس انجیرهای دستچین مغازه آموزش میدادیم؛ اگر بخواهیم آن را وسط باغ انجیر ببریم چه؟ حالا علاوهبر انجیرهای تازه، انجیرهای گندیده هم خواهیم داشت که بااینکه نرم هستند، اما نمیتوان آنها را خورد.
چه کار میشود کرد؟ خب این یک مدلِ یادگیری ماشین است، پس میتوان با اضافه کردن دادههای جدید درباره انجیرهای گندیده، آن را بهتر کرد، مگرنه؟
راستش داستان به این سادگیها نیست. همانطور که در تصویر زیر میبینید، با اضافه کردن دادههای مربوط به انجیرهای گندیده، کل نمودار خطی به هم میریزد و این یعنی ما باید سراغ مدل دیگری، مثلا نمودار سهمی برویم.
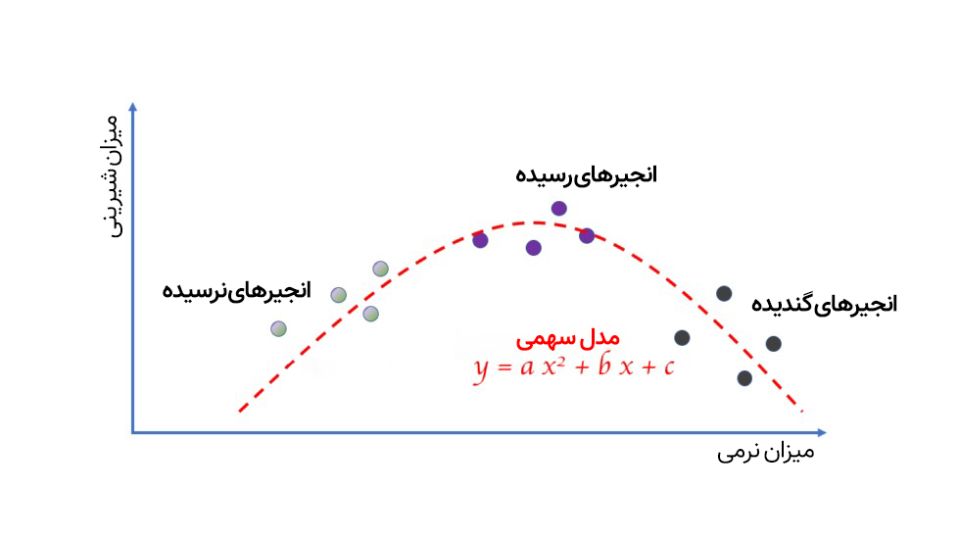
البته این مثال مسخرهای است، اما به خوبی نشان میدهد نوع مدلی که برای یادگیری ماشین انتخاب میکنیم، نوع و محدودیت یادگیری آن را تعیین میکند. بهعبارت سادهتر، اگر میخواهید چیز پیچیدهتری را یاد بگیرید، باید سراغ مدلهای پیچیدهتری بروید.
چالش اصلی یادگیری ماشین، ایجاد و انتخاب مدل مناسب برای حل مسئله است
با این حساب، چالش اصلی یادگیری ماشین، ایجاد و انتخاب مدل مناسب برای حل مسئله است. ما به مدلی نیاز داریم که بهقدری پیچیده باشد که بتواند روابط و ساختارهای بسیار پیچیده را نشان دهد و در عین حال به قدری ساده باشد که بتوانیم با آن کار کنیم و آموزشش بدهیم. برای همین، اگرچه اینترنت، گوشیهای هوشمند و چیزهایی از این دست، دسترسی به حجم عظیمی از داده را ممکن کردهاند، ما هنوز برای استفاده از این دادهها باید سراغ مدلهای مناسب برویم.
و این دقیقا جایی است که ما به نوع دیگر هوش مصنوعی، یعنی یادگیری عمیق نیاز پیدا میکنیم.
یادگیری عمیق (Deep Learning)
یادگیری عمیق نوعی یادگیری ماشین است که از یک نوع خاصی از مدل به نام «شبکههای عصبی عمیق» (Deep Neural Networks) استفاده میکند.
شبکههای عصبی نوعی مدل یادگیری ماشین هستند که از ساختاری مشابه نورونهای مغز انسان برای انجام محاسبات و پیشبینی استفاده میکنند. نورونها در شبکههای عصبی در لایههای مختلف طبقهبندی میشوند و هر لایه یک سری محاسبات ساده انجام میدهد و پاسخ آن را به لایهی بعدی منتقل میکند. هر چه تعداد لایهها بیشتر باشد، میتوان محاسبات پیچیدهتری انجام داد.
شبکههای عصبی عمیق بهخاطر تعداد زیاد لایههای نورونی «عمیق» نامیده میشوند
مثلا برای مثال انجیرها، یک شبکهی ساده با چند لایه نورون کافی است تا جواب مسئله را پیشبینی کند. اما شبکههای عصبی عمیق دهها یا حتی صدها لایه دارند و دقیقا به همین دلیل به آنها عمیق میگویند. با این همه لایه میتوانید مدلهای بینهایت قدرتمندی بسازید که قادرند بینیاز از قوانین تعیینشده توسط انسانها، انواع و اقسام مفاهیم پیچیده را خودشان یاد بگیرند و از پس مسائلی که کامپیوترها قبلا از حل آنها عاجز بودند، برآیند.
اما به جز تعداد لایه، عامل دیگری نیز باعث موفقیت شبکههای عصبی شده و آن آموزش است.
وقتی از «حافظه» مدل صحبت میکنیم، منظورمان مجموعهای از پارامترهای عددی است که بر نحوهی پاسخدهی مدل به سوالات، نظارت میکند. از این رو، وقتی از آموزش مدل حرف میزنیم، منظورمان تغییر و تنظیم این پارامترها بهگونهای است که مدل بهترین پاسخ ممکن را به سوالات ما بدهد.
مثلا با مدل انجیرها، ما سعی داشتیم معادلهای برای رسم یک خط بنویسیم که یک مسئلهی رگرسیون ساده است و فرمولهایی وجود دارند که میتوانند تنها در یک مرحله، جواب سوال ما را پیدا کنند. اما مدلهای پیچیدهتر طبیعتا به مراحل بیشتری نیاز دارند. یک شبکهی عصبی عمیق میتواند میلیونها پارامتر داشته باشد و مجموعه دادهای که براساس آن آموزش دیده ممکن است با میلیونها مثال روبهرو شود؛ برای این مدل، هیچ راهحل یکمرحلهای وجود ندارد.
میتوان کار را با یک شبکه عصبی ناقص شروع و در ادامه آن را بهتر کرد
خوشبختانه برای این چالش، یک ترفند عجیب وجود دارد؛ اینکه میتوان کار را با یک شبکهی عصبی ضعیف و ناقص شروع کرد و بعد با انجام تغییرات، آن را بهبود بخشید. آموزش مدلهای یادگیری ماشین با این روش شبیه این است که از دانشآموزان مرتب امتحان بگیریم. هر بار جوابی را که مدل فکر میکند صحیح است با جوابی که واقعا صحیح است، مقایسه میکنیم و به آن نمره میدهیم. بعد سعی میکنیم مدل را بهتر کرده و دوباره از آن امتحان بگیریم.
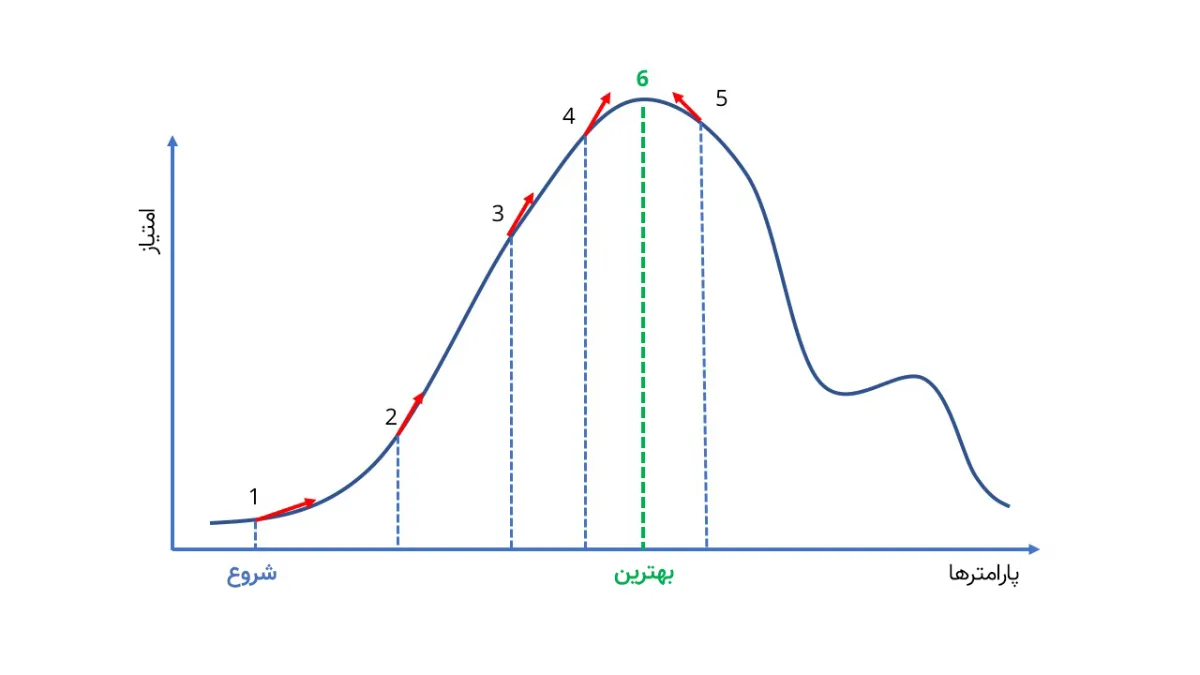
اما از کجا بدانیم چه پارامترهایی را باید تغییر دهیم و میزان این تغییرات چقدر باشد؟ شبکههای عمیق یک ویژگی جالب دارند که بهموجب آن، نه تنها میتوانیم برای بسیاری از انواع مسائل، نمرهی آزمون بهدست آوریم، بلکه میتوانیم بهطور دقیق حساب کنیم با تغییر هر پارامتر، نمرهی آزمون چقدر تغییر میکند. بدینترتیب، آنقدر پارامترها را تغییر میدهیم تا بالاخره به نمرهی کامل ۲۰ برسیم و مدل دیگر جایی برای بهبود نداشته باشد. به این کار اغلب تپهنوردی (Hill Climbing) گفته میشود، چون اگر همینطور به بالا رفتن از تپه ادامه دهید، سرانجام به نوک قله میرسید و صعود بیشتر ممکن نیست.
برای بهبود شبکه عصبی از روش «تپهنوردی» استفاده میکنند
این روش بهبود شبکهی عصبی را آسانتر میکند. اگر شبکهی ما ساختار خوبی داشته باشد، دیگر لازم نیست هر بار با اضافه شدن دادههای جدید، کارمان را از نو شروع کنیم. میتوان کار را با همان پارامترهای موجود شروع کرد و بعد مدل را با دادههای جدید آموزش داد. برخی از برجستهترین مدلهای هوش مصنوعی امروزی، از ابزار تشخیص تصویر گربه فیسبوک گرفته تا آنچه فروشگاههای زنجیرهای Amazon Go برای انجام خریدهای بدون نیاز به فروشنده استفاده میکنند، براساس همین تکنیک ساده ایجاد شدهاند.

علاوهبراین، به کمک روش «تپهنوردی» میتوان از یک شبکهی عصبی آموزش دیده برای یک منظور خاص، برای هدف دیگری استفاده کرد. مثلا اگر هوش مصنوعی خود را برای تشخیص تصویر گربه آموزش داده باشید، میتوانید خیلی راحت آن را برای تشخیص تصویر سگ یا زرافه تعلیم دهید.
انعطافپذیری شبکههای عصبی، حجم انبوه دادههای اینترنتی، رایانش موازی و GPUهای قدرتمند رویای هوش مصنوعی را محقق کرده است
به خاطر همین انعطافپذیری شبکههای عصبی است که هوش مصنوعی در هفت، هشت سال گذشته به پیشرفتهای بزرگی دست پیدا کرده است. از آن طرف هم اینترنت مدام درحال تولید حجم انبوهی از داده است و رایانش موازی درکنار پردازندههای گرافیکی قدرتمند، کار با این حجم از داده را ممکن کرده است. و در نهایت، بهکمک شبکههای عصبی عمیق توانستیم از این مجموعه داده برای تولید مدلهای یادگیری ماشین بسیار پیچیده و قدرتمند استفاده کنیم.
بدینترتیب، تمام کارهایی که انجامشان در زمان آلن تورینگ تقریباً غیرممکن بود، حالا بهراحتی امکانپذیر است.
کاربرد هوش مصنوعی
حالا که با انواع هوش مصنوعی و سازوکار آنها آشنا شدیم، سوال بعدی این است که در حال حاضر با آن چه کاری میتوانیم بکنیم؟ کاربرد هوش مصنوعی بهطور کلی در چهار زمینه تعریف میشود: تشخیص اجسام، تشخیص چهره، تشخیص صدا و شبکههای مولد.
تشخیص اجسام (Object Recognition)
شاید بتوان گفت حوزهای که یادگیری عمیق بیشترین و سریعترین تاثیر را در آن داشته، بینایی ماشین (Computer Vision)، بهویژه در تشخیص اجسام مختلف در تصاویر است. همین چند سال پیش، وضعیت پیشرفت هوش مصنوعی در زمینهی تشخیص اجسام به قدری اسفبار بود که در کاریکاتور زیر بهخوبی نمایش داده شده است.

مرد: میخوام که وقتی کاربر عکس میگیره، اپلیکیشن بتونه تشخیص بده که عکس مثلا تو پارک ملی گرفته شده…
زن: حله. فقط کافیه یه نگاهی به جیآیاس بندازم. یه چند ساعت بیشتر وقت نمیبره.
مرد: …و اینکه مثلا توی عکس پرنده هم بوده یا نه.
زن: خب واسه این یه تیم پژوهشی لازم دارم با پنج سال زمان.
امروزه، تشخیص پرندهها و حتی نوع خاصی از پرنده در عکس آنقدر کار آسانی است که حتی یک دانشآموز دبیرستانی هم میتواند آن را انجام دهد. یعنی در این چند سال چه اتفاقی افتاده است؟
ایدهی تشخیص اشیا توسط ماشین را میتوان به راحتی توصیف کرد، اما اجرای آن دشوار است. اجسام پیچیده از مجموعههایی از اجسام سادهتر ساخته شدهاند که آنها نیز خود از شکلها و خطوط سادهتری ایجاد شدهاند. مثلا چهرهی افراد از چشم و بینی و دهان تشکیل شده که خود اینها هم از دایره و خطوط و غیره تشکیل شدهاند. پس برای تشخیص چهره لازم است که الگوهای اجزای چهره را تشخیص داد.
هر جسم پیچیدهای از مجموعهای از اجسام و الگوهای سادهتری ساخته شده است؛ الگوریتمها به دنبال این الگوها هستند
به این الگوها ویژگی (Feature) میگویند و تا پیش از ظهور یادگیری عمیق، لازم بود آنها را دستی ایجاد کرد و کامپیوترها را طوری آموزش داد تا بتوانند آنها را پیدا کنند. مثلا، الگوریتم تشخیص چهرهی معروفی به نام «ویولا-جونز» (Viola-Jones) وجود دارد که یاد گرفته ابرو و بینی معمولا از اعماق چشم روشنتر هستند؛ درنتیجه، الگوی ابرو و بینی شبیه یک طرح T شکل روشن با دو نقطهی تاریک برای چشمها است. الگوریتم هم برای تشخیص چهره در تصاویر دنبال این الگو میگردد.
الگوریتم ویولا-جونز خیلی خوب و سریع کار میکند و قابلیت تشخیص چهرهی دوربینهای ارزان مبتنی بر همین الگوریتم است. اما بدیهی است که تمام چهرهها از این الگوی ساده پیروی نمیکنند. چندین تیم از پژوهشگران برجسته مدتها روی الگوریتمهای بینایی ماشین کار کردند تا آنها را تصحیح کنند؛ اما آنها نیز همچنان ضعیف و پر از باگ بودند.
تا اینکه پای یادگیری ماشین، بهویژه نوعی شبکهی عصبی عمیق به اسم «شبکهی عصبی پیچشی» (Convolutional Neural Network) معروف به CNN به میان آمد و انقلاب بزرگی در الگوریتمهای تشخیص اجسام به وجود آورد.
شبکههای عصبی پیچشی یا همان CNNها، ساختار خاصی دارند که از روی قشر بینایی مغز پستانداران الهام گرفته شده است. این ساختار به CNN اجازه میدهد تا به جای اینکه تیمهای متعددی از پژوهشگران بخواهند سالها صرف پیدا کردن الگوهای درست بکنند، خودش با یادگیری مجموعه خطوط و الگوها، اشیای حاضر در تصاوری را تشخیص دهد.
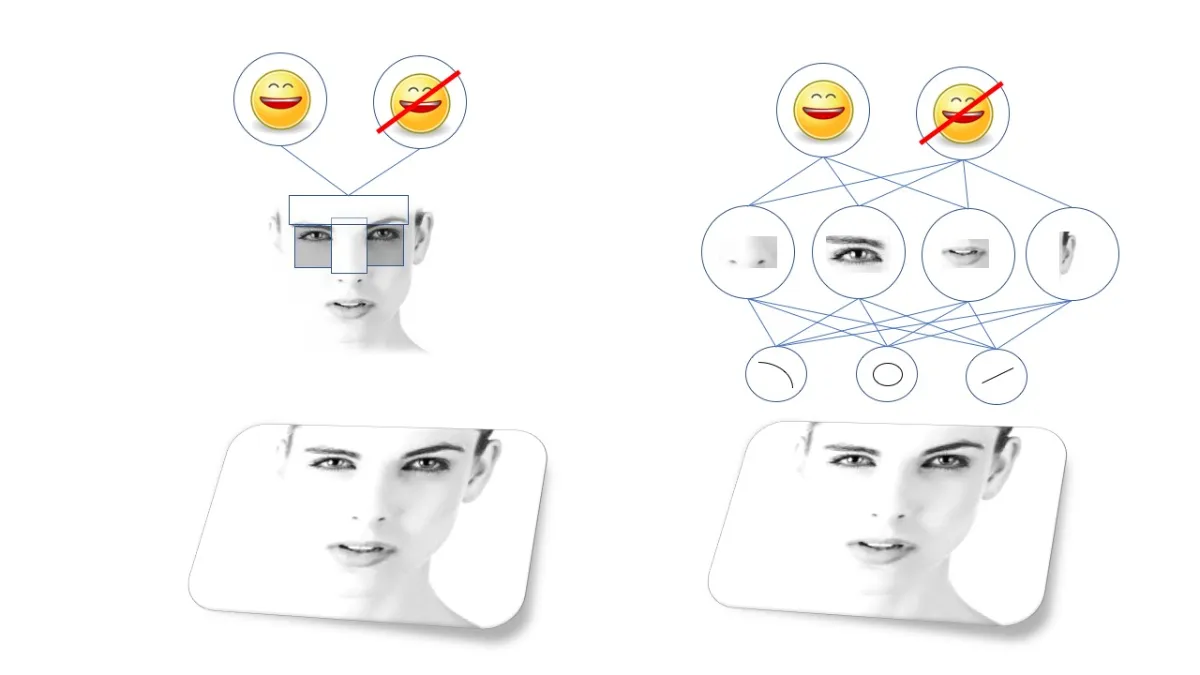
شبکههای CNN برای استفاده در بینایی ماشین فوقالعادهاند و خیلی زود پژوهشگران توانستند آنها را برای تمام الگوریتمهای تشخیص بصری، از گربههای داخل تصویر گرفته تا عابران پیاده از دید دوربین خودروهای خودران، آموزش دهند.
علاوهبراین، قابلیت CNNها بهخاطر سازگاری بیدردسر با هر مجموعه داده باعث فراگیری و محبوبیت سریع آنها شده است. فرایند تپهنوردی را به خاطر دارید؟ اگر دانشآموز دبیرستانی ما بخواهد الگوریتمش نوع خاصی از پرنده را تشخیص دهد، تنها کافی است یکی از چندین شبکهی بینایی ماشین را که بهصورت متنباز و رایگان دردسترس است، انتخاب کرده و بعد آن را براساس مجموعه دادهی خودش آموزش دهد، بدون آنکه لازم باشد از ریاضی و فرمولهای پشت پردهی این شبکه سر در بیاورد.
تشخیص چهره (Face Recognition)
فرض کنید میخواهیم شبکهای را آموزش دهیم که نه تنها بتواند چهرهها را بهطور کلی تشخیص دهد(یعنی بتواند بگوید در این عکس، انسان وجود دارد)، بلکه بتواند تشخیص دهد که این چهره دقیقا متعلق به کیست.
برای این کار، شبکهای را که قبلا برای تشخیص کلی چهرهی انسان آموزش دیده است، انتخاب میکنیم. بعد، خروجی را عوض میکنیم. یعنی به جای اینکه از شبکه بخواهیم چهرهای خاص را در میان جمعیت تشخیص دهد، از آن میخواهیم توصیفی از آن چهره را بهصورت صدها عددی که ممکن است فرم بینی یا چشمها را مشخص کند، به ما نشان دهد. شبکه از آنجایی که از قبل میداند اجزای تشکیلدهندهی چهره چیست، میتواند این کار را انجام دهد.
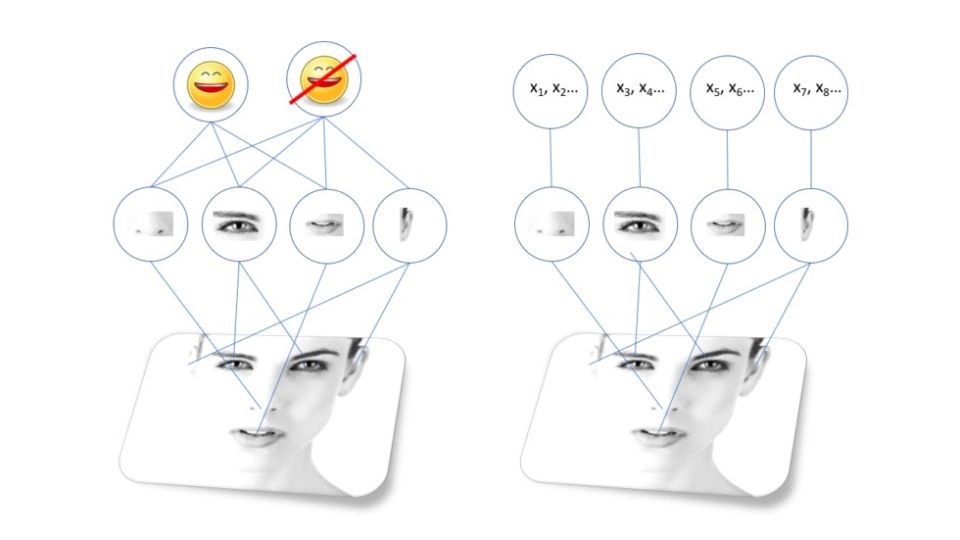
البته که ما این کار را به طور مستقیم انجام نمیدهیم؛ بلکه شبکه را با نشان دادن مجموعهای از چهرهها و بعد مقایسهی خروجیها با یکدیگر آموزش میدهیم. همچنین میتوانیم به شبکه یاد دهیم چطور چهرههای یکسانی را که شباهت زیادی به هم دارند و چهرههای متفاوتی را که اصلا شبیه هم نیستند، توصیف کند.
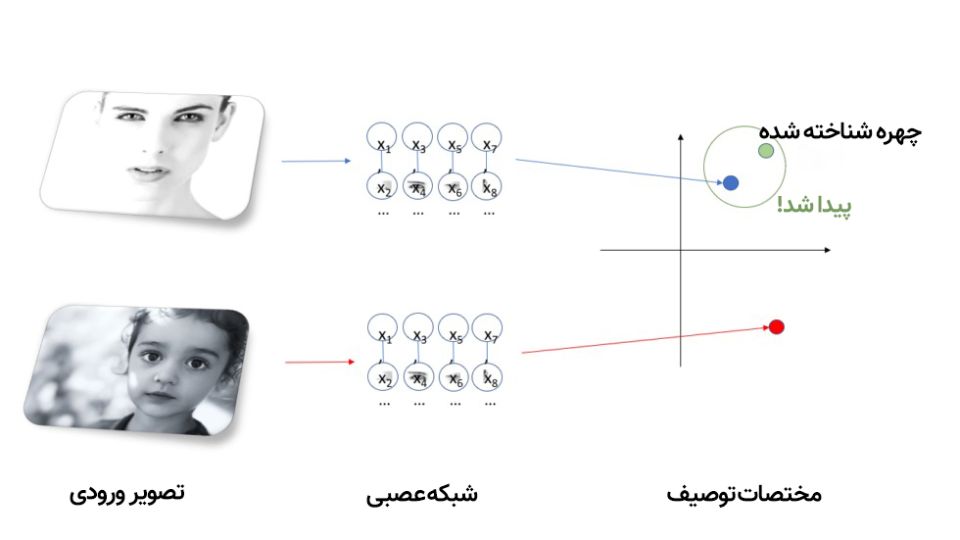
حالا تشخیص چهره آسان میشود؛ ابتدا، تصویر چهرهی اول را به شبکه میدهیم تا آن را برایمان توصیف کند. بعد، تصویر چهرهی دوم را به شبکه میدهیم و توصیف آن را با توصیف چهرهی اول مقایسه میکنیم. اگر دو توصیف به هم نزدیک باشد، میگوییم که این دو چهره یکی هستند. بدینترتیب، از شبکهای که فقط میتوانست یک چهره را تشخیص دهد به شبکهای رسیدیم که میتواند هر چهرهای را تشخیص دهد!
شبکههای عصبی عمیق بهطرز فوقالعادهای انعطافپذیر هستند
شبکههای عصبی عمیق دقیقا بهخاطر همین ساختار منعطف بهشدت کاربردی هستند. به کمک این تکنولوژی، انواع بسیار زیادی از مدلهای یادگیری ماشین برای بینایی کامپیوتر توسعه یافتهاند و اگرچه کاربرد آنها متفاوت است، بسیاری از ساختارهای اصلی آنها براساس شبکههای CNN اولیه نظیر Alexnet و Resnet ساخته شده است.
جالب است بدانید برخی افراد از شبکههای تشخیص چهره حتی برای خواندن خطوط نمودارهای زمانی استفاده کردهاند! یعنی به جای اینکه بخواهند برای تجزیهوتحلیل داده، یک شبکهی سفارشی ایجاد کنند، شبکهی عصبی متنبازی را طوری آموزش میدهند تا بتواند به شکل خطوط نمودارها هم شبیه چهرهی انسانها نگاه کند و الگوها را توصیف کند.
این انعطافپذیری عالی است، اما بالاخره جایی کم میآورد. برای همین، حل برخی مسائل به نوع دیگری از شبکه نیاز دارد که در ادامه با آنها آشنا میشوید.
تشخیص گفتار (Speech Recognition)
شاید بتوان گفت تکنیک تشخیص گفتار بهنوعی شبیه تشخیص چهره است، به این صورت که سیستم یاد میگیرد به چیزهای پیچیده به شکل مجموعهای از ویژگیهای سادهتر نگاه کند. در مورد گفتار، شناخت جملهها و عبارات از شناخت کلمات حاصل میشود که آنها هم خود به دنبال تشخیص هجاها یا بهعبارت دقیقتر، واجها میآیند. بنابرین وقتی میشنویم کسی میگوید «باند، جیمز باند» درواقع ما داریم به دنبالهای از صداهای متشکل از BON+DUH+JAY+MMS+BON+DUH گوش میدهیم.
در حوزهی بینایی ماشین، ویژگیها بهصورت مکانی سازماندهی میشوند که ساختار CNN هم قرار است همین مکانها را تشخیص دهد. اما درمورد تشخیص گفتار، ویژگیها بهصورت زمانی دستهبندی میشوند. افراد ممکن است آهسته یا سریع صحبت کنند، بیآنکه نقطهی شروع یا پایان صحبتشان معلوم باشد. ما مدلی میخواهیم که مثل انسانها بتواند به صداها در همان لحظه که ادا میشوند، گوش دهد و آنها را تشخیص دهد؛ بهجای اینکه منتظر بماند تا جمله کامل شود. متاسفانه برخلاف فیزیک، نمیتوانیم بگوییم مکان و زمان یکی هستند و داستان را همینجا تمام کنیم.
اگر با دستیار صوتی گوشیتان کار کرده باشید، احتمالا زیاد پیش آمده که Siri یا گوگل اسیستنت بهخاطر شباهت هجاها، حرف شما را اشتباه متوجه شده باشد. مثلا به گوگل اسیستنت میگویید «what’s the weather»، اما فکر میکند از او پرسیدهاید «what’s better». برای اینکه این مشکل حل شود، به مدلی نیاز داریم که بتواند به دنبالهی هجاها در بستر متن توجه کند. اینجا است که دوباره پای یادگیری ماشین به میان میآید. اگر مجموعهی کلمات ادا شده بهاندازه کافی بزرگ باشد، میتوان یاد گرفت که محتملترین عبارات کدامها هستند و هرچه تعداد مثالها بیشتر باشد، پیشبینی مدل بهتر میشود.
برای این کار، از شبکه عصبی بازگشتی یا همان RNN استفاده میشود. در اکثر شبکههای عصبی مانند شبکههای CNN که برای بینایی کامپیوتر به کار میروند، اتصالات نورونها تنها در یک جهت و از سمت ورودی به خروجی جریان دارد. اما در یک شبکهی عصبی بازگشتی، خروجی نورونها را میتوان به همان لایه که در آن قرار دارند یا حتی به لایههای عمیقتر فرستاد. بدینترتیب، شبکههای RNN میتوانند صاحب حافظه شوند.
شبکه CNN یکطرفه است، اما شبکه RNN حافظه داخلی دارد
شبکهی CNN یکطرفه است؛ به آن یک تصویر بهعنوان ورودی بدهید تا توصیف تصویر را بهصورت خروجی به شما تحویل دهد. اما شبکهی RNN به نوعی حافظهی داخلی دسترسی دارد و یادش میماند که قبلا چه تصاویری بهصورت ورودی به آن داده شده و میتواند پاسخهایش را هم مرتبط با چیزی که دارد میبیند و هم با چیزهایی که قبلا دیده، ارائه دهد.
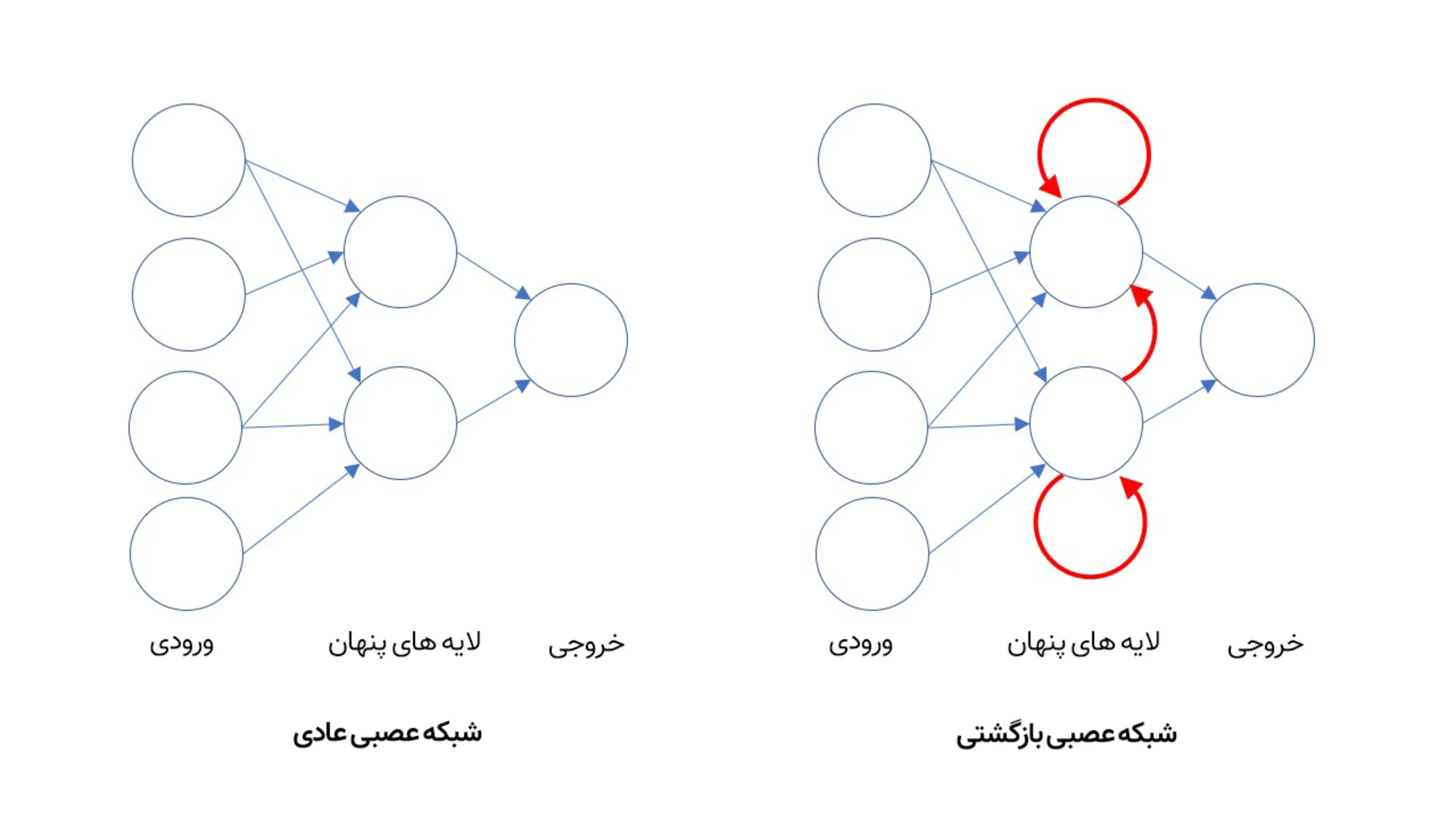
حافظهی RNN باعث میشود این شبکه نه تنها به تکتک هجاها به محض ادا شدن «گوش دهد»، بلکه میتواند یاد بگیرد که چه نوع هجاهایی کنار هم مینشینند تا یک کلمه را تشکیل دهند و همینطور میتواند پیشبینی کند که چه نوع عبارات و جملههایی محتملتر هستند. درنتیجه، شبکه RNN به دستیار صوتی یاد میدهد که گفتن «what’s the weather» از «what’s better» محتملتر است و متناسب با همین پیشبینی، به شما پاسخ میدهد.
به کمک RNN میتوان بهخوبی گفتار انسان را تشخیص داد و آن را به متن تبدیل کرد؛ عملکرد این شبکهها بهقدری بهبود یافته که از نظر دقت تشخیص حتی از انسانها هم بهتر عمل میکنند. البته دنبالهها فقط در صدا نمایان نمیشوند. امروزه از شبکههای RNN برای تشخیص دنبالهی حرکات در ویدیوها نیز استفاده میشود.
دیپفیک و شبکههای مولد (Deepfakes and Generative AI)
تا اینجای مطلب فقط داشتیم دربارهی مدلهای یادگیری ماشینی صحبت میکردیم که برای تشخیص به کار میروند؛ مثلا از مدل میخواستیم به ما بگوید در این تصویر چه میبیند یا چیزی را که گفته شده، درک کند. اما این مدلها قابلیتهای بیشتری دارند. همانطور که احتمالا از کار کردن با چتباتها و پلتفرم Dall-E متوجه شدید، مدلهای یادگیری عمیق این روزها میتوانند برای تولید محتوا هم به کار روند!
حتما نام دیپفیک (Deep Fake) را زیاد شنیدهاید؛ ویدیوهای جعلی که در آن افراد مشهور چیزهایی میگویند یا کارهایی میکنند که به نظر واقعی میرسد، اما اینطور نیست. دیپفیک هم نوع دیگری از هوش مصنوعی مبتنیبر یادگیری عمیق است که در محتوای صوتی و تصویری دست میبرد و آن را بهدلخواه تغییر میدهد تا نتیجهی نهایی چیزی کاملا متفاوت از محتوای اولیه باشد.

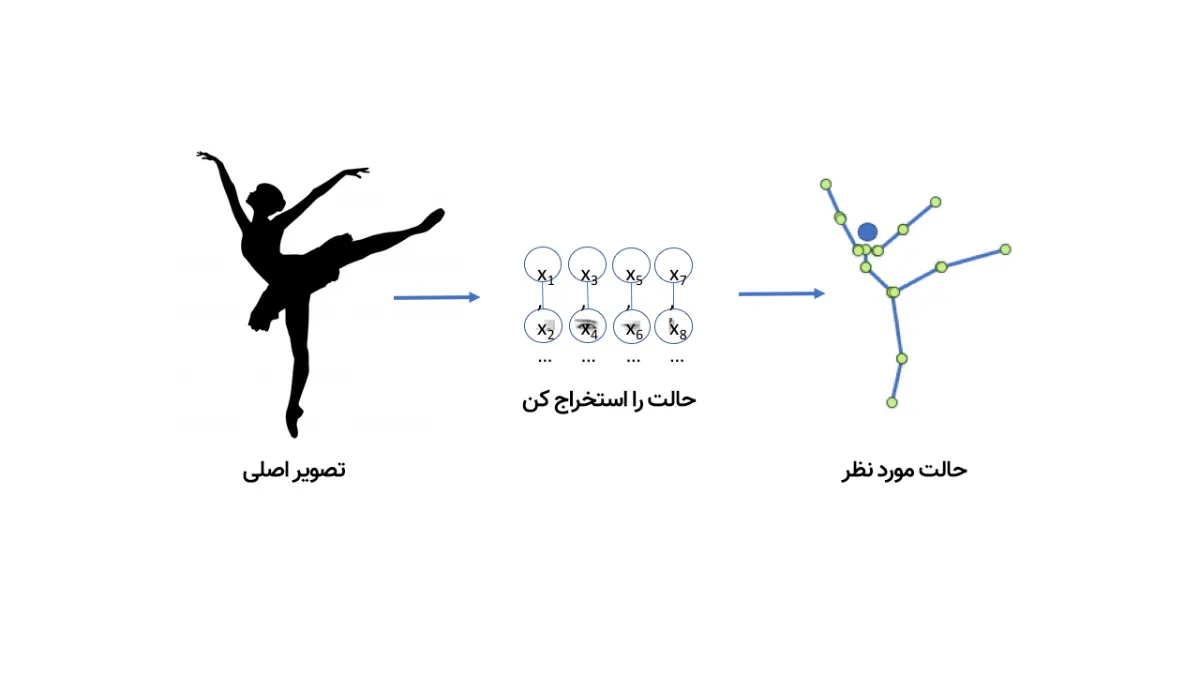
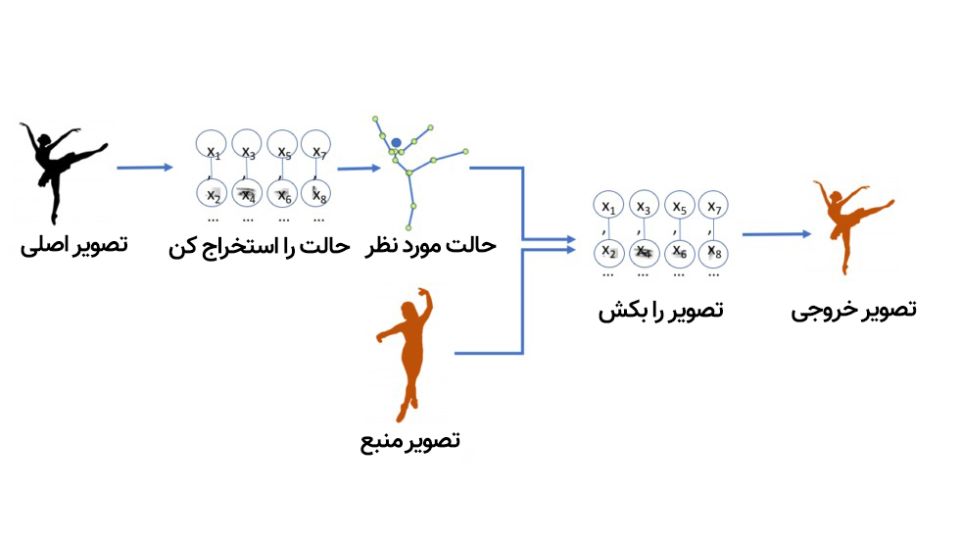
به این ویدیوی دیپفیک نگاه کنید؛ مدلی که در ساخت این دیپفیک بهکار رفته میتواند ویدیوی رقص یک فرد را تجزیهوتحلیل کند و بعد با پیدا کردن الگوها، همان حرکات موزون را در ویدیوی دوم روی فرد دیگری پیاده کند؛ طوری که فرد حاضر در ویدیوی دوم دقیقا شبیه ویدیوی اول به رقص درمیآید.
با تمام تکنیکهایی که تا اینجا توضیح دادیم، آموزش شبکهای که تصویر یک فرد در حال رقص را دریافت کند و بتواند بگوید دستها و پاهایش در چه موقعیت مکانیای قرار دارند، کاملا شدنی است. این شبکه همچنین یاد گرفته که چطور پیکسلهای یک تصویر را به موقعیت قرار گرفتن دستها و پاها مربوط کند. با توجه به اینکه برخلاف مغز واقعی، شبکهی نورونی هوش مصنوعی صرفا دادههایی هستند که در یک کامپیوتر ذخیره شدهاند، بیشک این امکان وجود دارد که این داده را برداشته و برعکس این فرایند عمل کنیم؛ یعنی از مدل بخواهیم از موقعیت دست و پا، پیکسلها را به دست آورد.
به مدلهای یادگیری ماشین که میتوانند دیپفیک بسازند یا مثل Dall-E و Midjourney، متن توصیفی را به تصویر تبدیل کنند، مدل مولد (Generative) میگویند. تا بدینجا، از هر مدلی که حرف زدیم از نوع تمیزدهنده (Discriminator) بود؛ به این معنی که مدل به مجموعهای از تصاویر نگاه میکند و تشخیص میدهد کدام تصویر گربه و کدام گربه نیست؛ اما مدل مولد همانطور که از نامش پیدا است، میتواند از توصیف متنی گربه، تصویر گربه تولید کند.
مدلهای مولدی که برای «بهتصویر کشیدن» اجسام ساخته شدهاند، از همان ساختار CNN به کار رفته در مدلهای تشخیص همان اجسام استفاده میکنند و میتوانند دقیقا به همان روش مدلهای یادگیری ماشین دیگر آموزش ببینند.
چالش ساخت مدل مولد تعریف سیستم امتیازدهی برای آن است
اما نکتهی چالشبرانگیز آموزش مدلهای مولد، تعریف سیستم امتیازدهی برای آنها است. مدلهای تمیزدهنده با پاسخ درست و نادرست آموزش میبینند؛ مثلا اگر تصویر سگ را گربه تشخیص دهند، میتوان به آنها یاد داد که پاسخ نادرست است. اما چطور میتوان به مدلی که تصویر گربهای را کشیده، امتیاز داد؟ مثلا اینکه چقدر نقاشیاش خوب است یا چقدر به واقعیت نزدیک است؟
اینجا جایی است که برای افراد بدبین به آینده و تکنولوژی، منظورم آنهایی است که معتقدند دنیا قرار است به دست رباتهای قاتل نابود شود، داستان واقعا ترسناک میشود. چراکه بهترین روشی که برای آموزش شبکههای مولد فعلا در اختیار داریم این است که به جای اینکه ما خودمان آنها را آموزش دهیم، اجازه دهیم شبکهی عصبی دیگری آنها را آموزش دهد؛ یعنی دو هوش مصنوعی رو در روی هم!
برای افرادی که به آینده رباتهای قاتل اعتقاد دارند، شبکه GAN داستان را ترسناک میکند
اسم این تکنیک، «شبکه مولد رقابتی» (Generative Adversarial Networks) یا GAN است. در این روش، دو شبکهی عصبی داریم که ضد یکدیگر عمل میکنند؛ از یک سمت شبکهای داریم که سعی دارد ویدیوی فیک بسازد (مثلا موقعیت مکانی دست و پاهای فرد در حال رقص را بردارد و روی فرد دیگری پیاده کند) و در سمت دیگر، شبکهی دیگری است که آموزش دیده تا با استفاده از مجموعهای از نمونه رقصهای واقعی، تفاوت بین ویدیوی واقعی و جعلی را تشخیص دهد.
در مرحلهی بعدی، این دو شبکه در نوعی بازی رقابتی مقابل همدیگر میگیرند که کلمهی «رقابتی» (Adversarial) از همینجا میآید. شبکهی مولد سعی می کند فیکهای قانعکنندهای بسازد و شبکهی تمیزدهنده سعی میکند تشخیص دهد که چه چیزی واقعی و چه چیزی جعلی است.
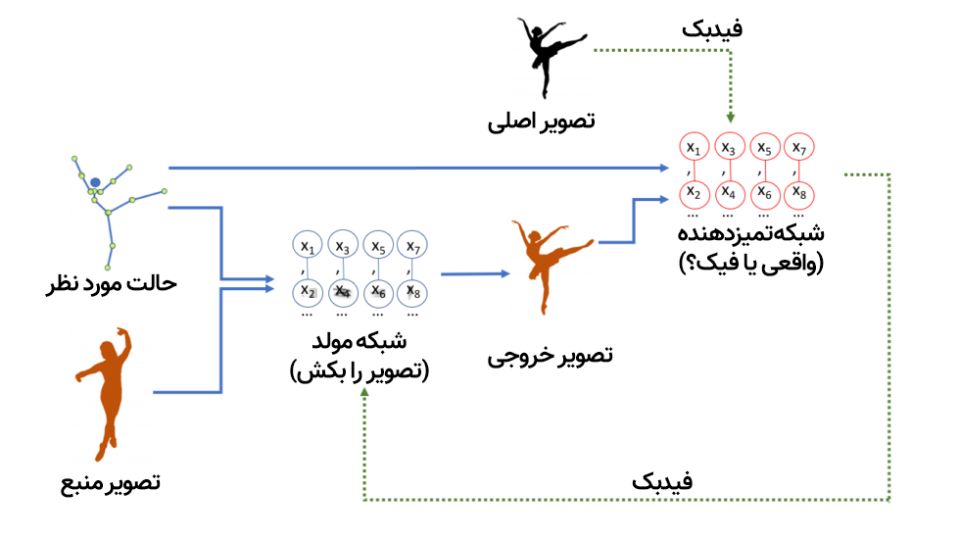
در هر دور آموزش، مدلها بهتر و بهتر میشوند. مثل این میماند که یک جعلکنندهی جواهر را در برابر یک کارشناس باتجربه قرار دهیم و حالا هر دو بخواهند با بهتر و هوشمندتر شدن، حریف خود را شکست دهند. درنهایت، وقتی هر دو مدل بهاندازهی کافی بهبود پیدا کردند، میتوان مدل مولد را بهصورت مستقل استفاده کرد.
مدلهای مولد در تولید محتوا، چه تصویری، چه صوتی، چه متنی و ویدیویی فوقالعادهاند؛ مثلا همین چتبات ChatGPT که اینروزها حسابی سروصدا بهپا کرده، از مدل زبانی بزرگ مبتنیبر مدل مولد استفاده میکند و میتواند تقریبا به تمام درخواستهای کاربران، از تولید شعر و فیلمنامه گرفته تا نوشتن مقاله و کد، در عرض چند ثانیه پاسخ دهد؛ آنهم بهگونهای که نمیتوان تشخیص داد پاسخ را انسان ننوشته است.
استفاده از شبکههای GAN از این جهت ترسناک است (البته برای افراد خیلی شکاک و بدبین!) که نقش انسانها در آموزش مدلها در حد ناظر است و تقریبا تمام فرایند یادگیری و آموزش برعهدهی هوش مصنوعی است.
نمونههای هوش مصنوعی
این روزها هوش مصنوعی را میتوان تقریبا در هر چیزی دید؛ از دستیارهای صوتی مثل Siri و الکسا گرفته تا الگوریتمهای پیشنهاد فیلم و آهنگ در نتفلیکس و اسپاتیفای و خودروهای خودران و رباتهایی که در خط تولید مشغول به کارند. اما در چند وقت اخیر، عرضهی برخی از نمونههای هوش مصنوعی، صحبت دربارهی این حوزه از تکنولوژی را سر زبانها انداختهاند که در ادامه بهطور مختصر به آنها اشاره میکنیم.
ChatGPT
ChatGPT نوعی چتبات آزمایشی یا بهتر است بگویم بهترین چتباتی است که تاکنون در دسترس عموم قرار گرفته است. این چتبات که نوامبر ۲۰۲۲ توسط شرکت OpenAI عرضه شد، مبتنیبر نسخهی ۳.۵ مدل زبانی GPT است.
در وصف شگفتیهایChatGPT حرفهای زیادی زده شده است. کاربران با تایپ درخواستهای خود در رابط کاربری بهشدت سادهی این چتبات، نتایج حیرتانگیزی دریافت میکنند؛ از تولید شعر و آهنگ و فیلمنامه گرفته تا نوشتن مقاله و کد و پاسخ به هر سؤالی که فکرش را بکنید؛ و تمام اینها تنها در کمتر از ده ثانیه انجام میشود.
حجم دادههایی که ChatGPT با آنها آموزش داده شده به حدی وسیع است که خواندن تمام آنها به «هزار سال عمر انسانی» نیاز دارد. دادههایی که در دل این سیستم پنهان شده، دانش بینهایت بزرگی را دربارهی جهانی که در آن زندگی میکنیم، در خود جای داده است و بههمین خاطر میتواند تقریبا به تمام سوالهای ما پاسخ دهد.
DALL-E
پلتفرم مولد تصویر DALL-E که نامش از ترکیب سالوادور دالی، نقاش سورئالیست و انیمیشن WALL-E پیکسار گرفته شده است، یکی از جذابترین محصولات توسعهیافته در OpenAI است که در آن، درخواستهای متنی کاربر در عرض چند ثانیه به آثار هنری شگفتانگیزی تبدیل میشود.

نسخهی اول DALL-E براساس مدل GPT-3 توسعه یافت و تنها به ایجاد تصاویری در ابعاد ۲۵۶ در ۲۵۶ پیکسل محدود بود. اما نسخهی دوم که در آوریل ۲۰۲۲ وارد فاز بتای خصوصی شد، جهش بزرگی در حوزهی مولدهای تصویر مبتنی بر هوش مصنوعی محسوب میشود. تصاویری که DALL-E 2 قادر به ایجاد آنها است، حالا ۱۰۲۴ در ۱۰۲۴ پیکسل هستند و از تکنیکهای جدیدی چون «inpainting» استفاده میکنند که در آن بخشهایی از تصویر به انتخاب کاربر با تصویر دیگری جایگزین میشوند.
جادوی DALL-E و دیگر مولدهای نظیر آن نه صرفاً به شناخت اشیا بهصورت جداگانه بلکه در درک فوقالعادهی آنها از روابط بین اشیا است؛ بهطوری که وقتی از آن میخواهید «فضانوردی سوار بر اسب» را ایجاد کند، خوب میداند منظور شما از این خواسته دقیقاً چیست.
درحالحاضر، افرادی که به ChatGPT دسترسی دارند، میتوانند از پلتفرم Dall-E نیز استفاده کنند.
Copilot
مایکروسافت در سال ۲۰۱۸ علاوهبر کسب حق امتیاز GPT-3، ازطریق پلتفرم گیتهاب با OpenAI وارد همکاری شد تا ابزار هوش مصنوعی Copilot را توسعه دهند. Copilot درون برنامه ویرایشگر کد اجرا میشود و به توسعهدهندگان در نوشتن کد کمک میکند.
استفاده از Copilot برای دانشجویان تأییدشده و گردانندگان پروژههای متنباز رایگان است و بهگفتهی گیتهاب، در فایلهایی که Copilot در آنها فعال است، نزدیک ۴۰ درصد کدها با این ابزار نوشته میشود. Copilot از مدل Codex شرکت OpenAI توسعه یافته که از نسل الگوریتم پرچمدار GPT-3 است.
Jukebox
سیستم Jukebox واقعاً حیرتانگیز است. کافی است به این بات ژانر آهنگ و نام هنرمند و متن آهنگ را بدهید تا نمونهای از یک آهنگ جدید را از صفر تا صد برایتان تولید کند. در پروفایل ساندکلاد OpenAI، به نمونههایی از آهنگهای تولیدشده با هوش مصنوعی Jukebox میتوانید گوش کنید. بهگفته این شرکت، متن آهنگها بهوسیلهی مدل زبانی و تعدادی از پژوهشگران نوشته شده است.
به جز Jukebox، ابزار هوش مصنوعی جدید گوگل بهنام MusicLM هم قادر به تولید آهنگ براساس توضیح متنی است؛ هرچند این ابزار هنوز در دسترس عموم قرار نگرفته است.
بهگفتهی گوگل، MusicLM در مجموع با دادههای متشکلاز ۲۸۰ هزار ساعت موسیقی آموزش داده شده تا یاد بگیرد براساس توضیحات دریافتی، آهنگهایی منسجم و پیچیده تولید کند. بهعنوان مثال این ابزار میتواند با ارائهی دستور «آهنگ جاز با یک تکنوازی ساکسیفون و یک تکخوان» یا «آهنگ تکنو دههی ۹۰ با بیس کم و ضربات قدرتمند»، آهنگهای بسیار باکیفیتی بسازد. خروجی این هوش مصنوعی بسیار چشمگیر است و به موسیقیهایی که هنرمندان انسانی ساختهاند، شباهت دارد.
Midjourney
میدجرنی هم مانند Dall-E نوعی بات تعاملی است که از یادگیری ماشین برای ایجاد تصاویر مبتنی بر متن استفاده میکند. این پلتفرم بر بستر دیسکورد قابل استفاده است و نسخهی رایگان آن به کاربران اجازهی چند درخواست محدود را میدهد. تمام درخواستهای کاربران دیگر و تصاویر تولید شده توسط میدجرنی در کانال دیسکورد این پلتفرم قابلمشاهده است.

یکی از جذابیتهای میدجرنی ساخت انواع مختلفی از یک تصویر یکسان است. به این ترتیب میتوان با کنار هم قرار دادن تصاویر یک انیمیشن جذاب به سبک «استاپ موشن» ساخت. از نظر برخی، تصاویر تولید شده با میدجرنی کیفیت و خلاقیت بیشتری از DALL-E دارند.
New Bing
«بینگ جدید» درواقع همان موتور جستوجوی نامآشنا و البته بداقبال مایکروسافت است که حالا به مدل هوش مصنوعی بسیار قدرتمندی مجهز شده تا هم تلاش دوبارهای باشد برای پایان دادن به یکهتازی چندین سالهی موتور جستوجوی گوگل و هم روش جستوجوی ما در اینترنت را بهطور کامل زیرورو و آنطور که مایکروسافت امیدوار است، بهتر از قبل کند.

اگر از قابلیتهای ChatGPT شگفتزده شدهاید، احتمالا از نسخهی بهکار رفته در بینگ بیشتر متحیر شوید؛ چراکه مایکروسافت میگوید مدل زبانی مورداستفاده در بینگ، GPT-4 است که به ۷۰۰ میلیارد پارامتر مجهز شده است. درضمن، چتبات بینگ به اینترنت متصل و اطلاعاتش همیشه بهروز است.
در بینگ جدید میتوانید سوال خود را با زبان طبیعی بپرسید تا هوش مصنوعی با همان زبان طبیعی شروع به پاسخگویی کند. مایکروسافت میگوید این مدل پاسخدهی به درخواستهای کاربران از سرچ سنتی، کاربردیتر و مفیدتر است.
LaMDA
LaMDA نیز مانند ChatGPT، چتبات مبتنیبر یادگیری ماشین است که برای صحبتکردن دربارهی هر نوع موضوعی طراحی شده است. این چتبات که مخفف Language Model for Dialogue Applications بهمعنای «مدل زبانی برای کاربردهای مکالمهای» است، برپایهی معماری شبکهی عصبی ترنسفورمر ایجاد شده که گوگل آن را در سال ۲۰۱۷ طراحی کرده بود؛ شبکهای که دقیقا در ساخت ChatGPT نیز به کار رفته است.
گوگل کماکان از عرضهی عمومی لمدا سرباز میزند؛ اما سال گذشته این چتبات پس از آنکه یکی از کارمندان گوگل مدعی شد به خودآگاهی رسیده، حسابی خبرساز شد. این فرد در ادعایی جنجالی که منجر به اخراجش از گوگل شد، گفت LaMDA احساسات و تجربیات ذهنی دارد؛ بههمیندلیل، خودآگاه است.
ادعای خودآگاه بودن LaMDA هم از طرف گوگل و هم از سمت متخصصان حوزهی هوش مصنوعی قویا رد شده است. راستش تکنولوژی هوش مصنوعی هنوز تا رسیدن به سیستمهای خودآگاه فاصلهی زیادی دارد؛ فاصلهای که به اعتقاد بسیاری از کارشناسان، به ۵۰ سال میرسد.
PaLM
PaLM مخفف Pathways Language Model مدل زبانی دیگری از گوگل است که بهمراتب از لمدا پیچیدهتر است.
گوگل PaLM را در رویداد I/O 2022 همزمان با معرفی LaMDA 2 رونمایی کرد که بهتازگی در دسترس توسعهدهندگان قرار گرفته است. این مدل میتواند ازپسِ کارهایی برآید که LaMDA نمیتواند انجامشان دهد؛ کارهایی مثل حل مسائل ریاضی، کدنویسی، ترجمهی زبان برنامهنویسی C به پایتون، خلاصهنویسی متن و توضیحدادن لطیفه. موردی که حتی خود توسعهدهندگان را نیز غافلگیر کرد، این بود که PaLM میتواند استدلال کند یا دقیقتر بگوییم PaLM میتواند فرایند استدلال را اجرا کند.

PaLM به ۵۴۰ میلیارد پارامتر مجهز است که از LaMDA چهار برابر و از مدل زبانی GPT-3 بهکار رفته در ChatGPT، سه برابر بیشتر است. PaLM بهدلیل بهرهمندی از چنین مجموعهی گستردهای از پارامتر، میتواند صدها کار مختلف را بدون نیاز به آموزش انجام دهد و شاید عدهای حتی وسوسه شوند که این مدل را نزدیکترین دستاورد بشر به «هوش مصنوعی قوی» بدانند، چون میتواند هر کار مبتنیبر تفکری را که انسان میتواند انجامش دهد، بدون آموزش خاصی انجام دهد.
خطرات هوش مصنوعی
هوش مصنوعی شبیه شخصیتهای خاکستری داستانها، نه صددرصد پلید است و نه صددرصد فرشتهی نجات و ابرقهرمان. در همان حال که زندگی بشر را سادهتر و تکنولوژیهای پیچیده و گرانقیمت را دردسترستر میکند، میتواند خطرات و چالشهایی نیز به دنبال داشته باشد که در ادامه به برخی از آنها اشاره میکنیم:
از بین رفتن برخی مشاغل بهخاطر اتوماسیون؛ از سال ۲۰۰۰ تاکنون، هوش مصنوعی و سیستمهای اتوماسیون ۱٫۷ میلیون شغل در حوزهی تولید را کنار گذاشتهاند. باتوجه به «گزارش ۲۰۲۰ آیندهی مشاغل» مجمع جهانی اقتصاد، انتظار میرود تا سال ۲۰۲۵، هوش مصنوعی جای ۸۵ میلیون شغل در سراسر جهان را بگیرد. مشاغلی مثل تجزیهوتحلیل داده، تلهمارکتینگ و خدمات مشتری، کدنویسی، حملونقل و خردهفروشی در خطر جایگزینی کامل با هوش مصنوعی هستند.

دستکاری اجتماعی از طریق الگوریتمها؛ هوش مصنوعی میتواند از طریق پلتفرمهای آنلاین نظیر شبکههای اجتماعی، رسانههای خبری و حتی فروشگاههای آنلاین، نظرات، رفتارها و احساسات افراد را تحتتاثیر قرار دهد. هوش مصنوعی همچنین میتواند با تولید محتوای جعلی یا گمراهکننده مثل ویدیوهای دیپفیک، به افراد آسیب برساند.
نظارت اجتماعی با هوش مصنوعی؛ دولتها و شرکتها بهکمک فناوری تشخیص چهره، ردیابی مکان و دادهکاوی که همگی مبتنیبر هوش مصنوعی است، میتوانند به نظارت گسترده از شهروندان و کارمندان بپردازند. این موضوع، حریم خصوصی، امنیت و آزادیهای مدنی افراد را تهدید میکند.
تعصبات ناشی از هوش مصنوعی؛ هوش مصنوعی میتواند تعصبات انسانی را در دادهها یا طراحی خود به ارث برده یا تقویت کند. این تعصبات میتواند منجر به نتایج ناعادلانه یا تبعیضآمیز برای گروههای خاصی از مردم از نظر نژادی، جنسیت، سن و غیره شود.
گسترش نابرابری اجتماعیاقتصادی؛ هوش مصنوعی میتواند بین افرادی که به مزایای آن دسترسی دارند و افرادی که از آنها بیبهرهاند، شکاف دیجیتالی ایجاد کند. هوش مصنوعی همچنین میتواند شکاف بین افراد ثروتمند و فقیر را با تمرکز ثروت و قدرت در دست عدهای که کنترل سیستمهای هوش مصنوعی را بهعهده دارند، افزایش دهد.

جنگافزارهای خودمختار؛ هوش مصنوعی میتواند در توسعهی سلاحهای مرگبار خودمختاری بهکار میرود که به اهداف بدون دخالت انسان شلیک کنند. درحالیکه عدهای میگویند با جایگزین کردن سربازهای انسان با رباتها، آمار تلفات کشور دارندهی این سلاحها کم میشود، در اختیار داشتن ارتشی که تلفات جانی روی دست کشور پیشرفتهتر نمیگذارد، انگیزهی بیشتری به آن کشور برای آغاز جنگ میدهد.
آینده هوش مصنوعی
تا چند سال پیش، آیندهی هوش مصنوعی، همین چتباتها و مولدهای تصویری چون ChatGPT و Midjourney بود که چند وقتی است در دسترس عموم قرار گرفتهاند و قرار است تا چند سال دیگر، به بهبودهای چشمگیری دست پیدا کنند. برای مثال، شرکت OpenAI در حال کار روی نسخهی چهارم مدل زبانی بزرگ GPT است که بهادعای افراد سیلیکونولی، قرار است در دنیای چتباتها معجزه کند. زمانی، تصور اینکه دو نفر با دو زبان متفاوت بتوانند با هم صحبت کنند و همزمان حرف یکدیگر را بفهمند تنها در داستانهای علمیتخیلی و بازیهای Mass Effect ممکن بود؛ اما بعید نیست تا چند وقت دیگر هوش مصنوعی چنین تصوری را به واقعیت تبدیل کند.

اینطور که پیدا است، هوش مصنوعی، مهمترین تکنولوژی آینده است و سناریوهای زیادی برای پیشرفت آن تعریف شدهاند؛ ازجمله:
هوش مصنوعی بیشتر با هوش انسانی ادغام میشود و تواناییهای ما را افزایش میدهد؛ مثلا رابطهای مغز و کامپیوتر، پردازش زبان طبیعی و بینایی ماشین میتوانند ارتباطات، یادگیری و ادراک ما را تقویت کنند.
هدف نهایی تمام پروژههای هوش مصنوعی رسیدن به AGI است
هوش مصنوعی خودمختارتر و با محیطهای پیچیده سازگارتر میشود؛ مثلا خودروهای خودران، خانههای هوشمند و دستیارهای رباتیک میتوانند با حداقل نظارت یا دخالت انسان کار کنند.
هوش مصنوعی در تولید محتوا یا ارائهی راهحلهای جدید، خلاقانهتر خواهد شد؛ مثلا شبکههای مولد رقابتی، الگوریتمها و تولید زبان طبیعی میتوانند تصاویر، آثار هنری، موسیقی یا متن واقعگرایانهای تولید کنند.
هوش مصنوعی با عوامل دیگر، چه انسانی چه ماشینی، وارد همکاری بیشتری میشود. مثلا، سیستمهای چندعاملی (MAS)، هوش گروهی (swarm intelligence) و یادگیری تقویتی میتوانند تصمیمگیری، حل مسئله و هماهنگیهای جمعی را ممکن کنند.
و البته هوش مصنوعی در بحث منابع داده، اصول طراحی، کاربردها و تاثیراتش متنوعتر و جامعتر خواهد شد. مثلا میتوان به پیشرفتهایی در هوش مصنوعی مسئولانه، هوش مصنوعی دروننما (explainable AI) که درون الگوهای پیچیدهی یادگیری هوشمند را برای انسانها آشکار میکند و هوش مصنوعی منصفانه و هوش مصنوعی قابلاعتماد، اشاره کرد.
اما هدف نهایی تمام افرادی که در حوزهی هوش مصنوعی کار میکنند، رسیدن به هوش مصنوعی قوی یا همان ماشینی است که بتواند در تمام فعالیتها از قابلیتهای فکری انسان جلو بزند. یعنی چیزی شبیه همان رباتهای خودآگاهی که در فیلمها میبینیم. البته تا رسیدن به چنین سطحی از هوش مصنوعی زمان زیادی باقی مانده؛ اگر نظر کارمندان OpenAI را بپرسید، به شما خواهند گفت تا ۱۳ سال آینده به هوش مصنوعی قوی میرسند، اما اکثر متخصصان این حوزه روی ۵۰ سال شرط بستهاند.
آیا هوش مصنوعی بشر را نابود میکند؟
خب با تمام این حرفها و پیشرفتهای چشمگیری که در حوزه هوش مصنوعی صورت گرفته، آیا باید تا چند وقت دیگر انتظار ظهور رباتهای قاتل مثل اسکاینت در فیلمهای ترمیناتور یا هال ۹۰۰۰ در فیلم ادیسه فضایی را داشته باشیم؟
اگر اهل تماشای مستندهای حیاتوحش باشید، احتمالا به این موضوع دقت کردهاید که در پایان تمام آنها، افرادی هستند که دربارهی اینکه چطور این همه زیبایی باشکوه قرار است به زودی بهدست انسانها نابود شود، صحبت میکنند. به همینخاطر هم فکر میکنم هر بحث مسئولانهای که دربارهی هوش مصنوعی صورت میگیرد، باید در مورد محدودیتها و پیامدهای اجتماعی آن نیز صحبت کند.
موفقیت هوش مصنوعی بهشدت به مدلهایی بستگی دارد که برای آموزش آنها انتخاب میکنیم
ابتدا بیایید بار دیگر بر محدودیتهای کنونی هوش مصنوعی تاکید کنیم؛ اگر فقط یک نکته باشد که امیدوارم از خواندن این مطلب به آن رسیده باشید، این است که موفقیت یادگیری ماشین یا هوش مصنوعی بهشدت به مدلهایی بستگی دارد که ما برای آموزش آنها انتخاب میکنیم. اگر انسانها این شبکهها را بدون رعایت استانداردها و اصول اولیه بسازند یا از دادههای اشتباه و گمراهکننده برای آموزش هوش مصنوعی استفاده کنند، آنوقت این مشکلات میتواند تاثیرات ناگواری بههمراه داشته باشند.

شبکههای عصبی عمیق بسیار انعطافپذیر و قدرتمند هستند، اما معجزه و جادویی نیستند. باوجود اینکه ممکن است از شبکههای عصبی عمیق هم برای RNN و هم CNN استفاده کرد، باید توجه داشت که ساختار زیربنایی این دو شبکه بسیار متفاوت است و تا اینلحظه نیاز بوده که انسانها آنها را از پیش تعریف کنند. بنابراین، اگرچه میتوان CNNای را که برای تشخیص خودرو آموزش دیده، برای تشخیص پرندگان از نو آموزش داد، اما نمیتوان این مدل را برای درک گفتار به کار برد.
بهعبارت سادهتر، مثل این است که ما متوجه شدهایم که قشر بینایی و قشر شنوایی چطور کار میکنند، اما مطلقا هیچ ایدهای نداریم که قشر مغز چطور کار میکند و اینکه اصلا برای فهم آن باید از کجا شروع کرد. و این یعنی ما احتمالا به این زودیها به هوش مصنوعی انسانگونه به سبک فیلمهای هالیوودی دست نخواهیم یافت. البته این به این معنی نیست که هوش مصنوعی فعلی نمیتواند تاثیرات اجتماعی منفی بهدنبال داشته باشد. برای همین، آشنایی با مفاهیم اولیهی هوش مصنوعی شاید حداقل کاری باشد که بتوان برای پیدا کردن راهی برای حل مشکلات هوش مصنوعی (و جلوگیری از نابودی زمین!) انجام داد.
برگرفته از:https://www.zoomit.ir/tech/344714-what-is-ai-everything-you-need-know-about-artificial-intelligence/
